







The Listings Crawler Plugin is a powerful automation tool for Osclass that enables you to extract and store classified listings from external websites directly into your marketplace database or JSON files. Save countless hours of manual data entry by automatically crawling product listings, real estate ads, vehicle classifieds, or any structured content from the web and preparing it for import into your Osclass site.
This plugin requires a solid understanding of HTML and CSS to properly configure and build crawlers. Ensure that your server can access the target URL, as some sites may have security measures that prevent crawling.
Plugin does not perform import into Osclass! Objective of plugin is to prepare data into JSON or Database storage for further processing.
Key Features
Intelligent Content Extraction
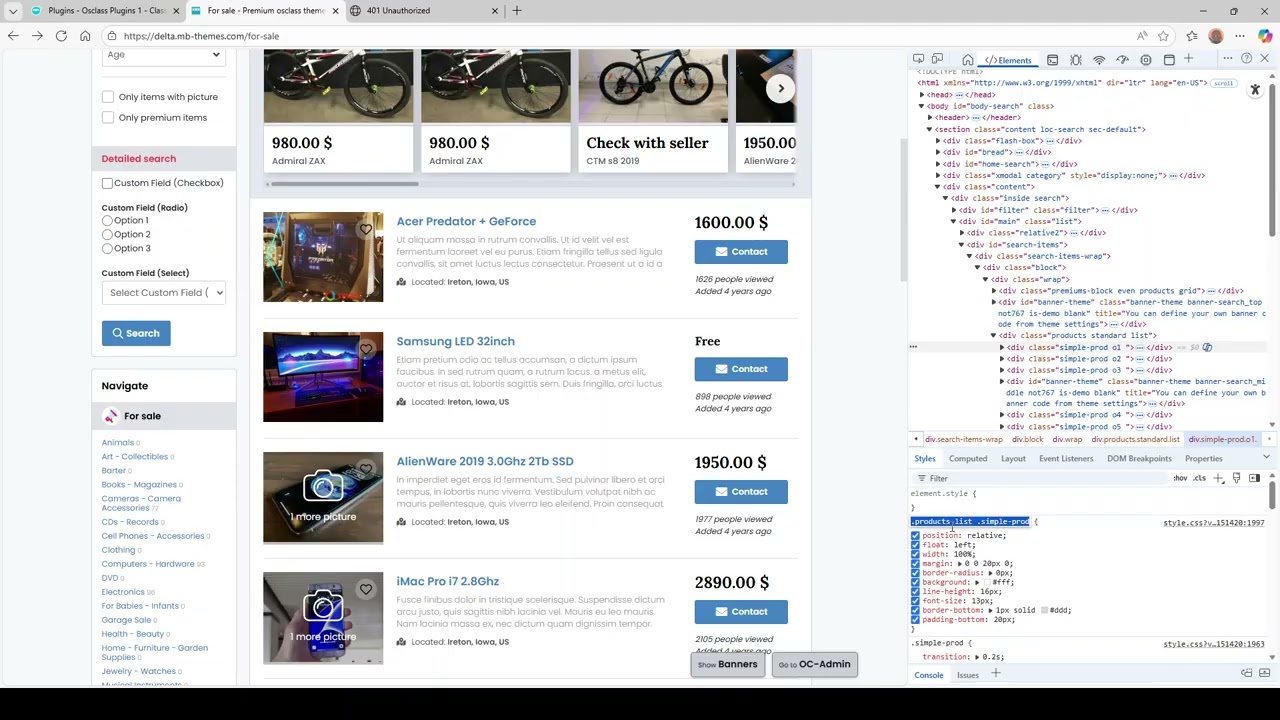
- CSS Selector-Based Mapping: Precisely target and extract any data field using CSS selectors with visual page structure analysis
- Dual Crawling Modes:
- Follow Links Mode: Extract from search/listing pages, then crawl individual item detail pages separately
- Direct Extraction Mode: Grab all data directly from a single page when complete details are available
- Multi-Source Support: Use comma-separated selectors for fallback options (OR logic) to ensure data capture
- Smart Image Handling: Automatically detects and extracts multiple images per listing (both src and data-src attributes)
- URL Analysis Tool: Built-in analyzer to examine page structure, test URL accessibility, and identify CSS selectors before crawling
Advanced Field Mapping (25+ Data Fields)
Extract and map comprehensive listing data including:
- Core Information: Title, description, locale/language
- Pricing Details: Price amount, currency with customizable delimiter parsing
- Visual Content: Multiple images with thumbnail and full-size support
- Contact Information: Name, email, phone with privacy visibility controls
- Location Data: Country, region, city, city area, ZIP code, full address
- Categorization: Automatic category assignment or default values
- Temporal Data: Publish date, expiration date with flexible format support
- Unique Identification: Automatic URL-based unique ID generation for deduplication
Flexible Configuration Options
- Static Default Values: Set fallback values for any field using simple double-quote syntax (e.g., "For Sale", "US", "[email protected]")
- Category & Location Intelligence: Automatically assign categories by name or ID, or use default mappings
- Currency & Price Parsing: Built-in delimiter support for accurate price extraction from combined price/currency strings
- Item Wrapper Filtering: Ignore specific page elements (like related items or user boxes) to avoid data conflicts
- Relative Selector Evaluation: All selectors evaluated relative to item wrapper for precise targeting
Automated Workflow & Scheduling
- Cron Integration: Schedule automatic crawling runs via Osclass cron jobs for hands-free operation
- Smart Deduplication: Update existing listings or skip duplicates based on unique URL-generated identifiers
- Full Refresh Mode: Option to completely replace old data with fresh crawls on each run
- Configurable Limits: Control items per run (recommended: up to 50) and total storage capacity (auto-cleanup of oldest items)
- Update vs. Skip Logic: Choose whether to update existing items with new data or skip them entirely
Server-Friendly Operation
- Adjustable Request Delays: Set pause intervals (100-2000ms recommended) between HTTP calls to respect target servers
- Custom User Agents: Configure browser mimicking to improve compatibility and avoid blocks
- Custom Headers: Add authentication or special headers via JSON configuration for protected content
- Rate Limiting: Built-in protections to prevent server overload on both source and target systems
- Server Accessibility Testing: Verify your server can access target URLs before setting up crawlers
Flexible Storage Options
- Database Storage: Store crawled items in dedicated database table (t_crw_item) for structured access
- JSON File Storage: Alternative file-based storage in oc-content/uploads/crawler for portability
- API Access: Secure API key system for programmatic data extraction and integration
- Retention Management: Automatic cleanup of oldest items when storage limits are reached
- Structured Data View: Browse extracted listings with searchable table including ID, title, category, contact info, images, and fetch date
Contact Data Management
- Smart Email Generation: Automatically generate random emails from extracted domains (e.g., extract @gmail.com and create [email protected])
- Privacy Controls: Configure email and phone visibility (public/private, yes/no, 1/0)
- Fallback Contacts: Set default contact information when none is found on source pages
- Email Domain Extraction: Intelligent domain detection for generating valid email addresses
Built-in Analysis & Testing Tools
- URL Analysis Feature: Test any URL before crawling to verify:
- Server accessibility (HTTP status codes, error detection)
- Response data quality (text extraction validation)
- Complete page structure with CSS selector hierarchy
- Element counts and direct text content
- Selector identification for easy mapping
- Visual Selector Browser: See all available CSS selectors on target pages with counts
- Fetch Validation: Detect 4xx/5xx errors, "Forbidden" responses, and security blocks before setup
Data Quality & Validation
- HTML Sanitization: Automatic HTML cleanup and conversion to clean text
- Date Format Parsing: Supports Y-m-d and Y-m-d H:i:s timestamp formats
- Unique ID Generation: MD5 hash-based unique identifiers from URLs for reliable deduplication
- Multi-Image Support: Extract all available images (12+ images per listing supported)
- Locale Support: Multi-language listing extraction capability
Perfect For
- Marketplace Aggregators: Build comprehensive classified platforms by extracting from multiple sources
- Content Migration: Transfer listings from old platforms to prepare for Osclass import
- Competitor Analysis: Monitor and extract competitor listings for market research
- Real Estate Portals: Aggregate property listings from various sources into centralized database
- Automotive Marketplaces: Extract vehicle listings automatically (cars, motorcycles, etc.)
- Job Boards: Crawl and aggregate job postings from multiple sites
- Price Comparison Sites: Extract product data with pricing for comparison engines
- Data Warehousing: Store classified ad data for analytics and business intelligence
How It Works
- Configure Crawler: Set up crawler with target URL and extraction mode (follow links or direct)
- Map Fields: Define CSS selectors for each data field you want to extract (title, price, images, etc.)
- Test & Analyze: Use built-in URL analyzer to verify server can access target and identify selectors
- Set Schedule: Configure cron for automatic runs or execute manually from admin panel
- Monitor Extraction: View extracted items in structured table with all data fields
- Access Data: Use stored database records or JSON files for import into Osclass listings
Technical Specifications
- Supported Formats: HTML pages with structured content accessible via HTTP/HTTPS
- Selector Engine: Standard CSS selectors (advanced pseudo-selectors like :has, :not, ~, + not supported)
- Selector Keywords: "this" keyword to reference item wrapper element itself
- Data Validation: Automatic HTML sanitization and text conversion for clean data
- Date Parsing: Supports Y-m-d and Y-m-d H:i:s formats, falls back to current timestamp
- Image Formats: Extracts both src and data-src attributes (lazy loading support)
- Locale Support: Multi-language listing extraction with locale field mapping
- Storage Formats: MySQL database tables or JSON file storage
- API Integration: RESTful API with key-based authentication
Use Cases
- Automated Extraction: Schedule nightly crawls to keep your database fresh with new listings
- Bulk Data Migration: One-time extraction of large listing databases from external sources
- Competitive Intelligence: Track changes and updates from competitor websites over time
- Multi-Source Aggregation: Combine listings from dozens of sources into single database
- Data Enrichment: Supplement existing data with additional fields from external sources
- Market Research: Collect pricing and inventory data for analysis
- Archive & Backup: Create regular snapshots of external listing data
Crawler Management Interface
- Multiple Crawlers: Create and manage unlimited crawlers for different sources
- Crawler List View: See all configured crawlers with ID, name, URL, and status
- Individual Settings: Each crawler has independent configuration for fields, limits, and scheduling
- Items Overview: Browse all extracted items across all crawlers in unified table
- Detail View: Examine complete extracted data for individual items including all 25+ fields
- Easy Editing: Modify crawler configuration anytime without losing extracted data
Requirements
- Osclass 8.x or higher
- PHP 7.4 or newer with cURL support
- MySQL database access for database storage mode
- Server with cron job capability (for automated scheduled runs)
- Write permissions to oc-content/uploads/crawler (for JSON storage mode)
- Target websites must be accessible from your server (no JavaScript-required pages or Cloudflare-protected sites)
- Server must support outbound HTTP/HTTPS requests
Limitations & Important Notes
- JavaScript-rendered content cannot be crawled (server-side HTML only)
- Sites with Cloudflare protection or similar security services may block requests
- Advanced CSS selectors (:has, :not, ~, +) are not supported
- Plugin extracts and stores data only - separate import step required to create actual Osclass listings
- Recommended maximum of 50 items per crawl run for optimal performance
- URL must be accessible from server backend (client-side JavaScript cannot be executed)
Transform your Osclass marketplace into a powerful data aggregator with the Listings Crawler Plugin. Extract thousands of listings from any website and store them ready for import with just a few CSS selectors.

 English
English Czech
Czech Slovak
Slovak







Verified & Genuine Reviews
All reviews on OsclassPoint come from real customers who have purchased the product. Only verified buyers can leave a rating or review.
To maintain quality and accuracy, every review is moderated before being published.